

Introduction
Debezium is an open-source distributed platform that provides Change Data Capture (CDC) for various databases. CDC is a technique for capturing changes (inserts, updates, deletes) made to a database and ensuring those changes are made available in real time to other systems. Debezium takes this concept a step further by offering database event streaming to systems like Apache Kafka, which can then be consumed by microservices, data lakes, and other real-time applications.
Debezium Architecture
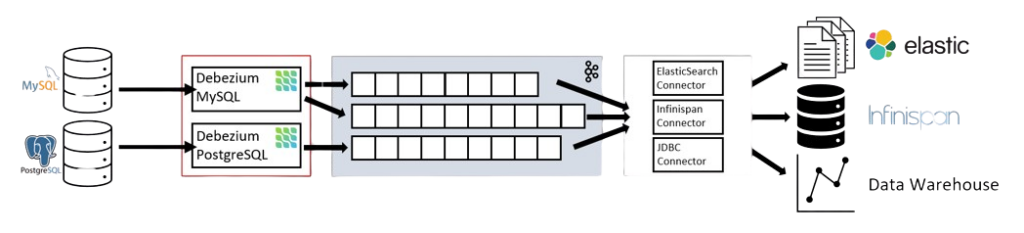
Image from https://debezium.io/documentation/reference/stable/architecture.html
List of Debezium Connectors
- MySQL
- PostgreSQL
- MongoDB
- SQL Server
- Oracle, etc…
Each connector listens to the transaction log or binlog of the database to detect changes as they occur. Once a change is detected, the connector converts it into an event and publishes it to Apache Kafka.
Kafka Connect
Debezium is built on top of Kafka Connect, a framework for integrating Kafka with external systems. Kafka Connect allows you to run connectors like the Debezium connectors in a fault-tolerant and scalable way.
Kafka Topics
Once the Debezium connector captures the changes from the database, it publishes them to Kafka topics. Each change (inserts, updates, deletes) is captured as an event, and the event is serialised and sent to a Kafka topic for further processing.
You can configure Debezium to stream changes to different Kafka topics depending on the source database or table.
Kafka Consumers
The next piece in the ecosystem are the Kafka consumers. These consumers are downstream services that read the data from Kafka topics. These consumers can be microservices, data warehouses, stream processing platforms.
Kafka consumers can process the change events from Kafka topics in real time, enabling use cases like:
- Real-time analytics
- Event-driven microservices (react to changes in the database)
- Data replication between systems
- Audit and logging (track data changes)
Debezium Use Cases
Debezium is used in a wide variety of scenarios where real-time data streaming and event-driven architectures are needed. Some common use cases include:
- Microservices Data Synchronization: In microservice architectures, different services often need to be synchronized with the same data. With Debezium, changes in one service’s database can be captured and pushed to Kafka topics, allowing other services to stay in sync.
- Real-time Analytics: By streaming database changes to Kafka, real-time data analytics platforms can consume the events and provide near-instant insights into business operations.
- Database Replication: Debezium can be used to replicate data between different databases, such as moving data from a primary relational database to a data lake or NoSQL store.
- Event-driven Systems: By turning database changes into events, Debezium enables the creation of event-driven systems that react to changes as they happen.
- Audit and Compliance: Debezium helps in tracking database changes for audit purposes. Each change event can contain metadata like the user who made the change, the timestamp, and the actual data change, making it useful for regulatory compliance.
How to deploy Debezium
- Select the appropriate Kafka Connect connector as per the Database.
- Enable the database to configure and allow Kafka Connect to read the data changes.
- The Debezium will monitor and share the database changes via Apache Kafka.
- The CDC streams are sent to the Kafka Topics.
- The Kafka sink side, the microservices in any languages, or other consumers like Apache Flink, ElasticSearch, NoSQL Databases, RabbitMQ, etc…
Conclusion
The eco-system for Debezium provides great flexibility, availability, security and performance for the CDC applications, as we saw above.
By integrating Debezium with these consumer components, organisations can create highly responsive, scalable, and event-driven architectures that respond to data changes in real time.
There are more ways to configure the Debezium architecture, but that is not mentioned in this blog.
For some of the information above and for more information, the good source of the Debezium eco-system is available at the web site – https://debezium.io/documentation/reference/stable/architecture.html
In Part – 2, we will look at how a sample database schema with the tables in the RDBMS like PostgreSQL can be configured, with Debezium for streaming data to the Apache Kafka and the consumer is consuming this real-time data in the sink on the opposite side of the Apache Kafka. Stay tuned!!!
This blog will also be accompanied with the different up-to-date configuration and other artefacts for these entire two parts blog series.

Leave a Reply